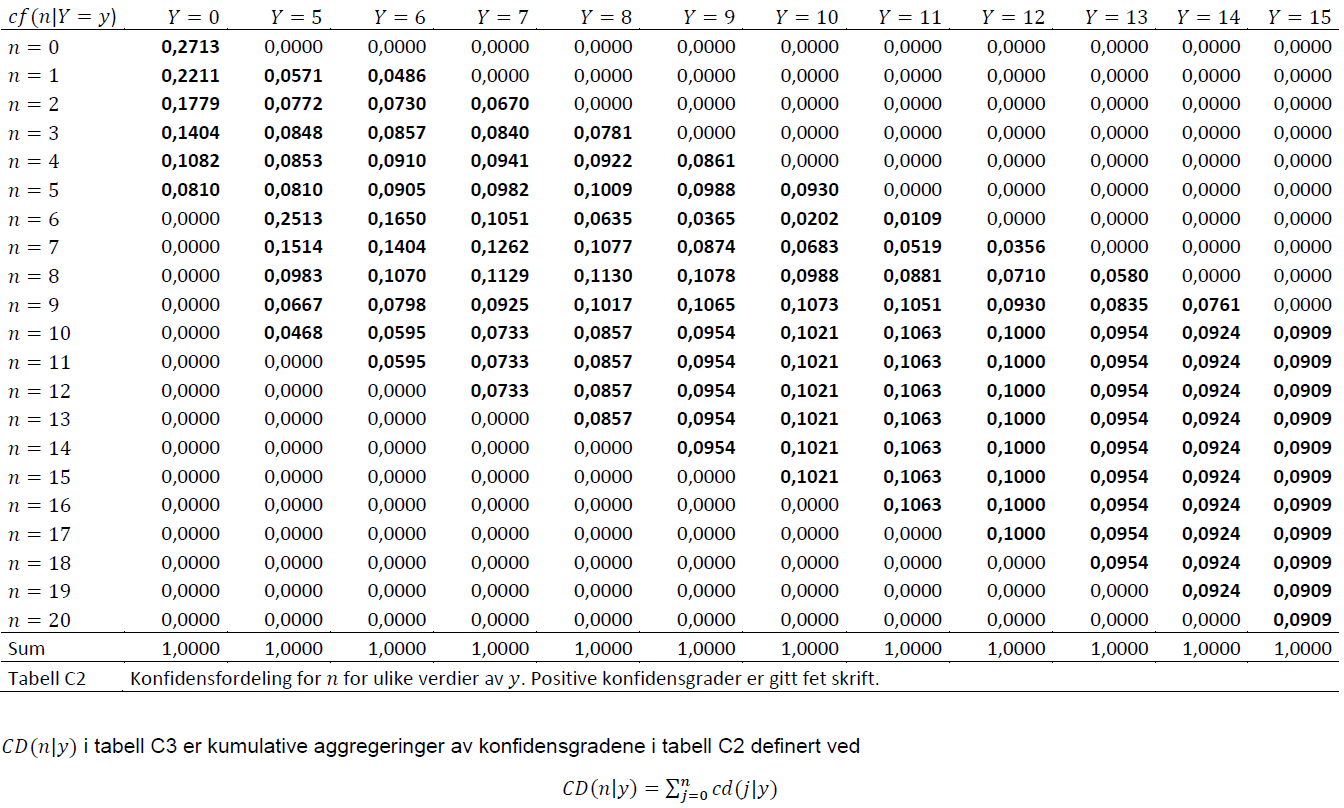
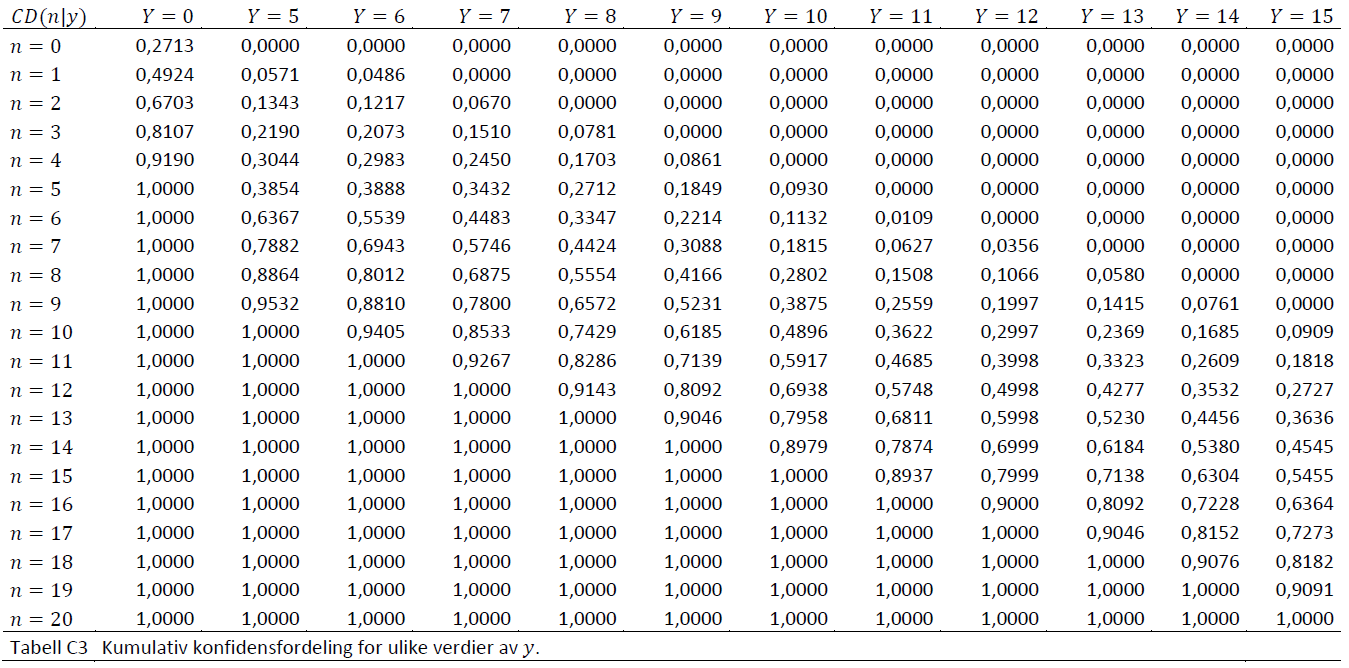
Konfidensialitet
Bakgrunn
Lov om offisiell statistikk og Statistisk sentralbyrå (LOV-2019-06-21-32) § 14 (tilgang til opplysninger for statistiske resultater og analyser) ledd (5) sier at «Taushetsplikten etter § 8 gjelder tilsvarende for den som får tilgang til opplysninger». Slike data kan kun utleveres til forskere i godkjente forskningsinstitusjoner og til offentlige myndigheter. Det stilles derfor strenge krav for tilgang til mikrodata, og søknad om tilgang til mikrodata for forskning er en lang prosess. Kriteriene for å søke om tilgang til registerdata for forskning kan du finne på SSBs sider om data til forskning.
Microdata.no er utviklet for å gjøre det mulig å få tilgang til mikrodata fra registre uten å måtte gå gjennom den omstendelige søknadsprosessen det er for å få data utlevert. Men det er en betingelse for en slik forenkling at sikkerheten og konfidensialiteten til mikrodataene er like godt ivaretatt som ved utlevering, helst bedre. Det har derfor fra begynnelsen vært et eksplisitt krav at brukerne ikke skal kunne se mikrodata eller på annen måte være i stand til å avsløre informasjon om enkeltpersoner. Når SSB publiserer offisiell statistikk er det aggregerte data. Likevel må SSB passe på ved ulike typer tiltak at det ikke er mulig å føre informasjon tilbake til enkeltpersoner eller andre typer statistiske enheter som statistikken dreier seg om.
De resultatene som microdata.no produserer for sine brukere, tabeller eller analyser, er i likhet med SSBs statistikk aggregerte data. Men uten begrensninger vil en bruker av microdata.no lett kunne produsere tabeller og andre typer statistiske resultater som SSB ikke ville kunne publisere. For å forhindre at det skjer er det innført flere typer tiltak som skal begrense mulighetene for å kunne avsløre informasjon som skal være konfidensiell.
Dette vedlegget vil beskrive de tiltakene som er implementert for å ivareta konfidensialitet i microdata.no. Tiltakene er basert på scenarier for hvordan konfidensialitet i microdata.no kan angripes eller utilsiktet komme i fare. Disse scenariene vil ikke bli beskrevet. Det vil bli lagt vekt på det som er nødvendig for at brukeren skal kunne forstå tiltakene og forholde seg til de statistiske resultatene på riktig måte.
De tiltakene som er beskrevet nedenfor er de som er implementert så langt. Det vil kunne komme flere tiltak etter hvert eller også justeringer av de tiltakene som er beskrevet nedenfor. Dette vedlegget vil bli oppdatert når det kommer endringer.
Tiltak 1: Minste populasjonsstørrelse
Det er ikke tillatt å definere undersøkelsespopulasjoner med færre enn 1000 personer. Forsøk på å definere slike populasjoner vil bli møtt med en melding av typen

Tiltak 2: Winsorisering
Winsorisering er en teknikk som ofte brukes i analyser for å hindre at ekstreme observasjoner skal få for stor innvirkning på analyseresultatene. Teknikken anvendes på alle numeriske variabler og består i å kutte av fordelingen i begge ender ved bestemte prosentiler. Vi benytter 2% winsorisering som betyr at de 1% høyeste verdiene settes til 99-prosentilen (nedre grenseverdi) og de 1% laveste verdiene settes til 1-prosentilen (øvre grenseverdi). Dette skjer kun ved visning av statistiske resultater, med utgangspunkt i den aktuelle populasjon som statistikken beregnes ut i fra.
Siden fordelingene til mange numeriske statistiske variabler er skjevfordelte, typisk med lange haler i øvre ende (eks. inntekter og formuer), vil winsorisering påvirke gjennomsnitt og standardavvik til en viss grad. Begge typer statistikker vil typisk bli estimert for lave. På den andre siden vil medianer, kvartiler og andre prosentiler ikke bli påvirket.
Eksempel: Betrakt følgende skript hvor målet er å lage deskriptive statistikker og histogram for aldersfordelingen i befolkningen per 1. januar 2010.
create-dataset befolkning
import db/BEFOLKNING_FOEDSELS_AAR_MND as f_årmnd
generate alder2010 = 2010 - int(f_årmnd/100)
summarize alder2010
histogram alder2010, discrete
Resultatet vil se slik ut:
summarize alder2010
| Variabel | mean | std | count | 1% | 25% | 50% | 75% | 99% |
|---|---|---|---|---|---|---|---|---|
| alder2010 | 38.7467 | 22.681 | 255743 | 1 | 21 | 37 | 55 | 89 |
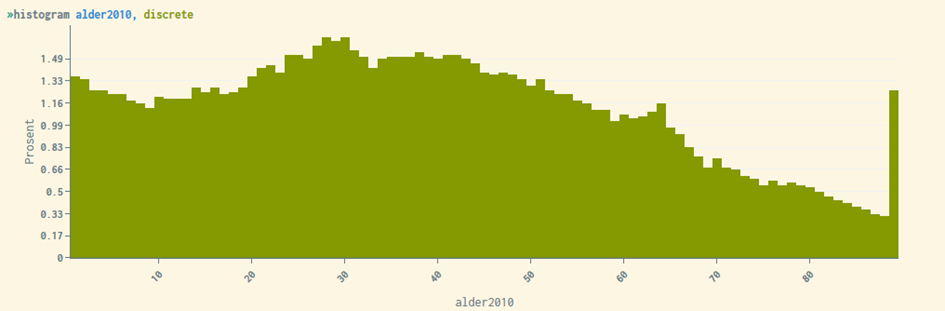
Alle som er eldre enn 89 år vil bli satt til 89 år og 0-åringer vil bli satt til 1 år. Dette er årsaken til den store søylen til høyre i histogrammet. 0-åringer er her kun dem født 1. januar 2010. Vi er oppmerksomme på at winsoriseringen kan skape problemer ved statistiske fremstillinger av de aller eldste. Det samme gjelder andre grupper som er definert ved å tilhøre halen i fordelingen til en numerisk variabel.
Winsorisering påvirker alle deskriptive statistikker og grafiske plott, og hindrer at de mest ekstreme verdiene blir synlige.
Aggregering av data (collapse):
Så lenge man bruker commandoen
collapse()til å aggregere et datasett opp til et nivå hvor deskriptiv statistikk winsoriseres, kjøres selve collapse-aggregeringen uten winsorisering. Aggregering fra arbeidsforhold til personnivå eller fra person- til familienivå er eksempler på aggregeringer som gjøres uten winsorisering. Bruk avcollapse()hvorby()-leddet angir en pseudonymisert variabel winsoriseres altså ikke i selve aggregeringssteget.
Men dersom mål-enhetstypen til
collapse()(angitt iby()-leddet) er en enhetstype gitt ved en vanlig ikke-pseudonymisert variabel, f.eks. kommune, fylke, næringstype, eller utdanningsnivå, vil beregninger gjort gjennomcollapse()være gjenstand for winsorisering. Grunnen til dette er at disse enhetstypene ikke vil bli winsorisert ved generering av deskriptiv statistikk. Derfor må altså winsoriseringen gjøres i forbindelse med selve aggregeringen.
Resultater som fremstilles gjennom regresjonsanalyser er ikke å betrakte som personidentifiserende informasjon. Ved slike analyser benyttes derfor de underliggende ikke-winsoriserte data. Regresjonsestimater vil derfor ikke bli påvirket av winsorisering.
Tiltak 3: Støylegging
Alle opptellinger av antall enheter i et datasett som vises i
forbindelse med diverse operasjoner, eller statistiske opptellinger som
vises gjennom blant andre kommandoene tabulate eller summarize
er støylagte. Summer av numeriske statistikkvariabler knyttet til
enhetene i for eksempel en tabellcelle, for eksempel inntekter, er
justert proporsjonalt med støyleggingen slik at gjennomsnittstall er
upåvirket. Der hvor støyleggingen resulterer i at antall enheter bak
summen blir 0, blir summen satt til 0 og gjennomsnittet, som da blir 0/0
blir satt til NaN.







Tiltak 4: Grafiske plott. Hexbinplott
Det er vanlig å bruke spredningsplott for å etablere et visuelt bilde av data eller også vise sammenheng mellom numeriske variabler. Slike plott kan være veldig avslørende, spesielt hvis det er få observasjoner i forhold til det grafiske området og for de punktene i plottet som ligger utenfor hovedmassen av punkter. Hvis vi for en enhet/person i populasjonen kjenner verdien på en av de variablene som spenner ut plottet kan vi ofte lese av verdien til den andre variabelen med for stor nøyaktighet.
For å hindre at dette kan skje har vi i microdata.no valgt å glatte slike plott med en glatteteknikk. For dette formålet har vi forsøksvis valgt å fokusere på en teknikk som kalles hexbin-plott. I et hexbin-plott deles det grafiske området inn i regulære sekskanter. Et eksempel på et hexbin-plott laget i microdata.no er følgende:
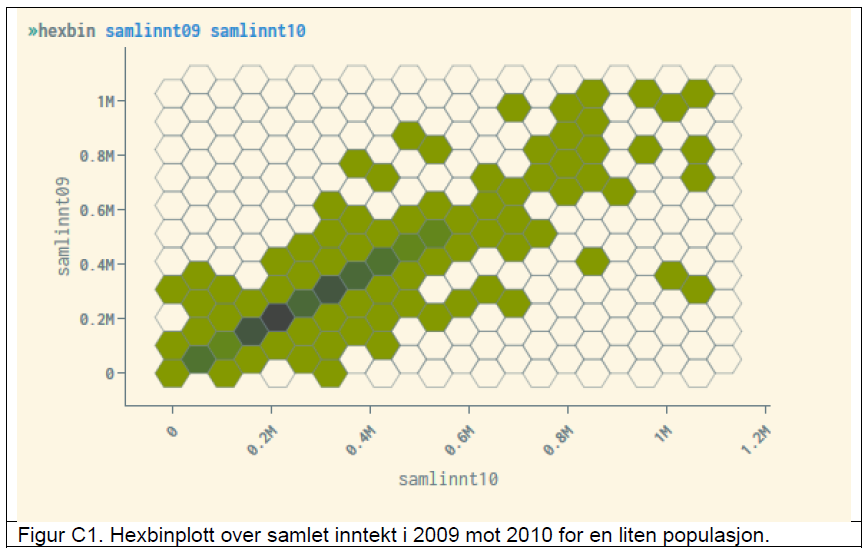
I et hexbin-plott skaleres det grafiske området på grunnlag av de største og minste verdiene som forekommer for de variablene som plottes. De største og minste verdiene er påvirket av winsoriseringen omtalt i tiltak 2. Sekskantene gis en farge eller fargetone som angir et intervall for hvor mange enheter det er i dem, for eksempel 30-59, 60-89 osv. Intervallet for antall enheter/personer hver fargetone representerer er like langt for hver fargetone og tilpasses automatisk av fordelingen i data.
Hexbin plot er under utprøving. I den versjonen som foreløpig er lagt ut er alle sekskanter hvor antall personer er færre enn 20% av det mest befolkede hexagonet blanket. Dette kriteriet vil bli justert så snart det er mulig å gi det prioritet.
Tiltak 5: Skjuling av tabeller med for mange lave verdier
Tabeller som lages ved kommandoen tabulate vil i noen tilfeller
kunne inneholde mange celler med lave verdier for antallet enheter.
Dette kan være problematisk ettersom det gjør det lettere å indirekte
identifisere individer ved å studere kombinasjoner av verdier for de
kategoriske variablene som utgjør en tabell. Et annet problem med slike
tabeller er at støyleggingen beskrevet under «Tiltak 3» gir en relativt
høy usikkerhet for de aktuelle celleverdiene (den prosentvise støyen
blir relativt stor ved små tall), slik at den statistiske nytteverdien
av tabellen blir lav.
I microdata.no opereres det med en grenseverdi på 50%, dvs. tabeller der mer enn 50% av cellene inneholder frekvensverdier lavere enn 5, vil bli stoppet. I tillegg vil det vises en feilmelding om dette.
Det er mulig å unngå problemet med tabeller som stoppes pga. for mange lave verdier: Ved å lage grovere inndelinger for de kategoriske variablene som utgjør tabellen, eller ved å øke størrelsen på tabellpopulasjonen, vil en kunne øke antallet enheter i hver celle og dermed komme under 50%-grensen slik at tabellen blir godkjent og vises.
Tiltak 6: Ikke tillatt med endringer som påvirker færre enn 10 enheter
Det er ikke tillatt å gjøre endringer i et datasett som påvirker færre
enn 10 enheter, gjennom bruk av kommandoene generate, replace eller
recode(). Om dette inntreffer, vil man få en feilmelding og kjøringen
vil stoppe.
Det er heller ikke tillatt å gjøre endringer som påvirker alle enheter bortsett fra et antall færre enn 10.
Eksempler:


Et viktig unntak er at man kan gjøre endringer som påvirker alle eller ingen enheter.
Eksempler (koden 9999 finnes ikke i datasettet):

(Merk at antallet missingverdier som rapporteres er ulikt antall
enheter i eksempelet over. Dette skyldes støyleggingen av
frekvensverdier, jfr. Tiltak 3. I praksis vil variabelen test bare
inneholde missingverdier.)

Ved bruk av recode, så gjelder regelen for hvert av omkodingsleddene i
uttrykket (man ser på hver av kodene det kodes til, og hvert av leddene
må kode om minst 10 observasjoner).
Eksempel:

Tiltak 7: Ikke tillatt med deskriptiv statistikk for populasjoner som utgjør færre enn 10
Deskriptiv statistikk gjennom kommandoene summarize eller summarize i
kombinasjon med tabulate kan ikke kjøres på populasjoner som utgjør
færre enn 10. Unntak er summer og frekvenser.
Eksempel:

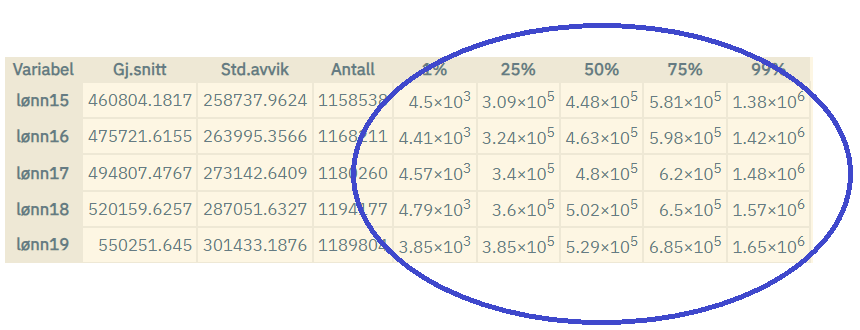
Tiltak 8: Median- og prosentilverdier vises kun med tresifret nøyaktighet
Median- og prosentilverdier viser faktiske verdier som kan knyttes til
enkeltpersoner (eller andre enheter). Derfor vises slike verdier kun med
tresifret nøyaktighet, og påvirker visningen av tall ved bruk av
kommandoene summarize, summarize i kombinasjon med tabulate, og grafer
der slike tall inngår.
Eksempler:

Tiltak 9: Konstantledd skjules fra regresjonsresultat dersom analysepopulasjonen har for unike kombinasjoner av kategoriske verdier
For å styrke konfidensialiteten ved regresjonsanalyser, er det en begrensning knyttet til analyser på datasett med for høy grad av unikhet. Hvis kombinasjoner av kategoriske variabelverdier i analysen utgjør veldig små grupper, vil konstantledd-estimatene bli skjult fra regresjonsresultatene. Analysen påvirkes ikke siden konstantleddet inngår i estimeringen.
Det er prinsippet for k-anonymity som benyttes på det underliggende analysedatasettet, definert av populasjonen og settet av forklaringsvariabler for den aktuelle analysen, der grenseverdien er satt til 5. Skjuling av konstantledd skjer altså for regresjoner som kjøres på datasett med færre enn 5 enheter med samme kombinasjon av variabelverdier.
Merk at kontinuerlige variabler inngår ikke ved vurderinger av unikhet, kun kategoriske variabler.
I tilfeller der tiltak 9 slår inn, og man ønsker å se konstantleddet, er det noen grep man kan foreta for å gjøre datasettet mindre unikt (slik at antallet unike kombinasjoner kommer over 5):
- Øke populasjonsstørrelsen
- Bruke grovere inndeling av kategorier
- Begrense antallet kategoriske forklaringsvariabler
Tiltak 10: Mikroaggregering og glatting før beregning av persentiler
Ved beregning av persentiler (f.eks. median) gjennomføres det en mikroaggregering av sorterte verdier i grupper av størrelse mellom 3 og 10 verdier i hver gruppe. Alle verdiene i samme gruppe blir erstattet med gjennomsnittsverdien i gruppen. Deretter glattes verdiene med sentrert glidende gjennomsnitt med periode mellom 3 og 10.