En enkel innføring i microdata.no
For å komme i gang med microdata.no, vil vi vise hvordan man lager en typisk statistikk gjennom noen av de mest grunnleggende kommandoene i verktøyet. Statistikkeksempelet vårt viser gjennomsnittsinntekten i Oslo, Bergen og Trondheim, og kjønnsfordelingen av gjennomsnittsinntekten i disse kommunene.
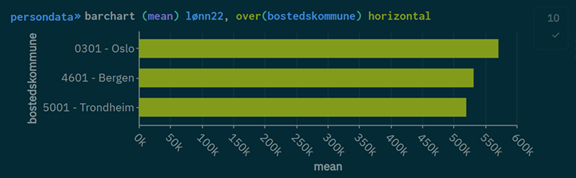
Gjennomsnittsinntekt i Oslo, Bergen og Trondheim
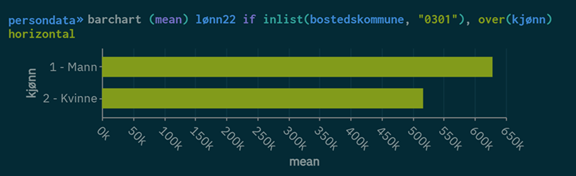
Gjennomsnittsinntekt i Oslo fordelt på kjønn
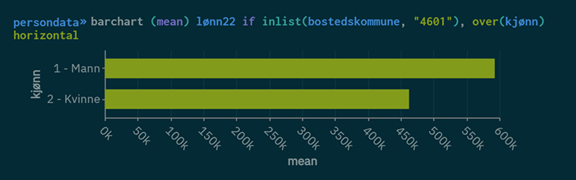
Gjennomsnittsinntekt i Bergen fordelt på kjønn
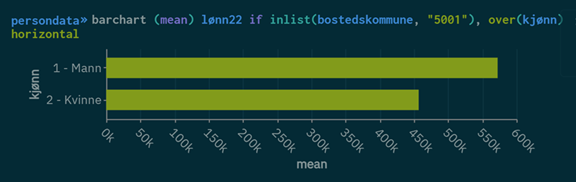
Gjennomsnittsinntekt i Trondheim fordelt på kjønn
Nedenfor vil vi punkt for punkt gå gjennom alle trinnene som trengs for å kunne lage en slik statistikk.
Opprette kobling til databank
require no.ssb.fdb:38 as db
Den første kommandoen som brukes er require, som kobler opp til SSBs databank, der alle variablene ligger. Den refereres til som db i skriptet og er nødvendig for å få tilgang til variabler for å videre bruke disse i et datasett.
Databank-versjon
Det siste tallet i no.ssb.fdb:38 står for versjonsnummeret. Siste versjon inneholder nyeste oppdateringer av variabler og årganger. Man får beskjed dersom man bruker en eldre versjon enn den nyeste:

Oppretting av datasett
create-dataset persondata
Denne kommandoen oppretter et nytt, tomt datasett gitt det valgfrie navnet persondata. Man får også opp dette datasettet på høyresiden av vinduet etter kommandoen er kjørt. For å fylle datasettet med innhold, kan du importere variabler fra databanken ved hjelp av import-kommandoen. Dette gjør det mulig å hente inn ønskede data til ditt nye datasett.
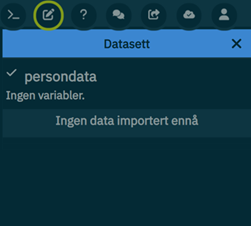
Første importerte variabel
import db/INNTEKT_WLONN 2022-12-31 as lønn22
Denne kommandoen importerer variabelen INNTEKT_WLONN fra databasen per 31. desember 2022 og gir den navnet lønn22, som representerer individers lønnsinntekt for 2022. Den dukker også opp i datasettet på høyresiden når kommandoen er kjørt.
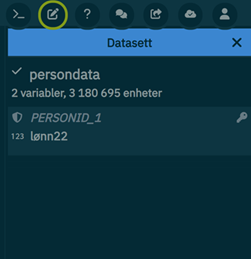
Dette er den første variabelen som blir importert og bestemmer derfor populasjonen i datasettet. Datasettet inneholder de som hadde lønnsinntekter i 2022. Denne variabelen har temporalitetstypen akkumulert, som betyr at datoene representerer årsinntekt per siste dag i året (31.12.xxxx). Man kan velge hvilken som helst dato innenfor det aktuelle året dersom man har akkumulerte verdier målt over et år. Verdiene man får ut vil bli de samme (akkumulert årsverdi).
Slik ser datasettet ut etter at første variabel er importert (illustrasjon):
| personID | lønn22 |
|---|---|
| 1 | 450 000 |
| 2 | 320 000 |
| 3 | 150 000 |
| 4 | 700 000 |
Andre importerte variabel
import db/BEFOLKNING_KOMMNR_FORMELL 2023-01-01 as bostedskommune
Etter lønnsvariabelen lønn22, importeres en variabel som angir individers bostedskommune. Denne kommandoen importerer variabelen BEFOLKNING_KOMMNR_FORMELL per 1. januar 2023. Den inneholder alle som er bosatte per 1.1.2023. Denne variabelen har temporalitetstype tverrsnitt, som betyr at alle som er registrert bosatt i en kommune i folkeregisteret per 1.1.xxxx, inkluderes. Variabler med denne typen temporalitet vil typisk måles over faste gjentakende datoer, i dette tilfellet 1/1 hvert år. Om man velger en annen dato, vil man ikke få ut noen opplysninger.

Hvordan import av nye variabler påvirker eksisterende datasett
Når du importerer nye variabler i datasettet ditt, blir alle rader fra det eksisterende datasettet beholdt (alle med verdi på lønn22, den første importerte variabelen). De nye variablene legges til basert på matchende rader mellom det eksisterende datasettet og de nye dataene. For eksempel, hvis du først har importert variabelen lønn22 (lønn for 2022), og deretter importerer variabelen bostedskommune, vil informasjon om bostedskommune bli lagt til for alle personer som allerede har en verdi for lønn22. Denne metoden kalles en left join. Slik ser datasettet ut etter at bostedskommune er importert (illustrasjon):
| personID | lønn22 | bostedskommune |
|---|---|---|
| 1 | 450 000 | "0301" (Oslo) |
| 2 | 320 000 | "4601" (Bergen) |
| 3 | 150 000 | "0301" (Oslo) |
| 4 | 700 000 | "5001" (Trondheim) |
Filtrering
Siden eksempelet vårt viser gjennomsnittlig inntektsfordeling i Oslo, Bergen og Trondheim, kan man filtrere datasettet slik at man kun beholder disse kommunene i datasettet. Da bruker man kommandoen keep if, og spesifiserer tallkodene for de tre kommunene separert med | (eller). Tallkodene finnes i variabelbeskrivelsen. Variabelen er alfanumerisk, og man må derfor bruke anførselstegn når man angir verdien.
Det er også mulig å bruke en filtrering direkte i statistikkkommandoen ved å legge til en if-betingelse bakerst (men før eventuelle opsjoner man har mulighet til å angi etter et komma). Da slipper man å bruke en slik keep if kommando.
keep if bostedskommune == "0301" | bostedskommune == "4601" | bostedskommune == "5001"
Etter denne kommandoen er kjørt, er det kun individer som er bosatt i Oslo, Bergen og Trondheim per 1. januar 2023 i datasettet, og individer som er bosatt i andre kommuner enn disse, er fjernet.
Analyse
For å finne gjennomsnittsinntekten i Oslo, Bergen og Trondheim, kan vi bruke kommandoen barchart med variablene lønn22 og bostedskommune. Denne kommandoen genererer et søylediagram som viser gjennomsnittsinntekten for de som er bosatt i Bergen, Trondheim og Oslo siden det er disse som er inkludert i datasettet.
barchart (mean) lønn22, over(bostedskommune) horizontal
barchart(mean) lønn22 spesifiserer at man ønsker å lage et søylediagram som viser gjennomsnittsverdien (mean) av variabelen lønn22
over(bostedskommune) grupperer dataene etter bostedskommune, slik at gjennomsnittsinntekten beregnes separat for hver av de spesifiserte kommunenene.
horizontal angir at søylediagrammet skal være horisontalt. Uten denne opsjonen ville diagrammet vært vertikalt som standard.
Kommandoen gir dette resultatet:
Innebygd hjelpefunksjon
Kommandoen help gir detaljert informasjon om kommandoer og bruken. For eksempel, ved å skrive help barchart, får man en forklaring på hvordan barchart-kommandoen fungerer, inkludert syntaks og eksempler.
help barchart gir dette resultatet:

Importering av flere variabler
import db/BEFOLKNING_KJOENN as kjønn
Dersom man ønsker å importere flere variabler, kan dette gjøres når som helst i skriptet. For å se kjønnsfordelingen på gjennomsnittsinntekt i bostedskommuner, kan man importere kjønn og bruke denne i analysen. Variabelen kjønn har verdien "1" for mann, og "2" for kvinne. Denne variabelen har temporalitetstypen fast, og man trenger derfor ikke spesifisere dato. Denne variabelen dukker også opp i samme datasett som man ser i vinduet til høyre etter kommandoen er kjørt.

Slik ser datasettet ut etter kjønn er importert (illustrasjon):
| personID | lønn22 | bostedskommune | kjønn |
|---|---|---|---|
| 1 | 450 000 | "0301" (Oslo) | "2" (Kvinne) |
| 2 | 320 000 | "4601" (Bergen) | "1" (Mann) |
| 3 | 150 000 | "0301" (Oslo) | "1" (Mann) |
| 4 | 700 000 | "5001" (Trondheim) | "2" (Kvinne) |
Gjennomsnittsinntekt i Oslo, Bergen og Trondheim fordelt på kjønn
Her brukes barchart-kommandoen for å lage et søylediagram per kommune, fordelt på kjønn
Gjennomsnittsinntekt i Oslo fordelt på kjønn
barchart (mean) lønn22 if inlist(bostedskommune, "0301"), over(kjønn) horizontal
inlist(): Denne betingelsen filtrerer dataen slik at kun observasjoner med den bestemte bostedskommunen inkluderes i analysen.
Gjennomsnittsinntekt i Bergen fordelt på kjønn
barchart (mean) lønn22 if inlist(bostedskommune, "4601"), over(kjønn) horizontal
Gjennomsnittsinntekt i Trondheim fordelt på kjønn
barchart (mean) lønn22 if inlist(bostedskommune, "5001"), over(kjønn) horizontal
Hele skriptet
require no.ssb.fdb:38 as db
create-dataset persondata
import db/INNTEKT_WLONN 2022-12-31 as lønn22
import db/BEFOLKNING_KOMMNR_FORMELL 2023-01-01 as bostedskommune
keep if bostedskommune == "0301" | bostedskommune == "4601" | bostedskommune== "5001"
//Gjennomsnittsinntekt for Oslo, Bergen og Trondheim
barchart (mean) lønn22, over(bostedskommune) horizontal
help barchart
import db/BEFOLKNING_KJOENN as kjønn
barchart (mean) lønn22 if inlist(bostedskommune, "0301"), over(kjønn) horizontal
barchart (mean) lønn22 if inlist(bostedskommune, "4601"), over(kjønn) horizontal
barchart (mean) lønn22 if inlist(bostedskommune, "5001"), over(kjønn) horizontal